题目描述
在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针。 例如,链表1->2->3->3->4->4->5 处理后为 1->2->5
解题思路
这道题做了比较久……感觉有一点点难写。
主要看下面这幅图理解
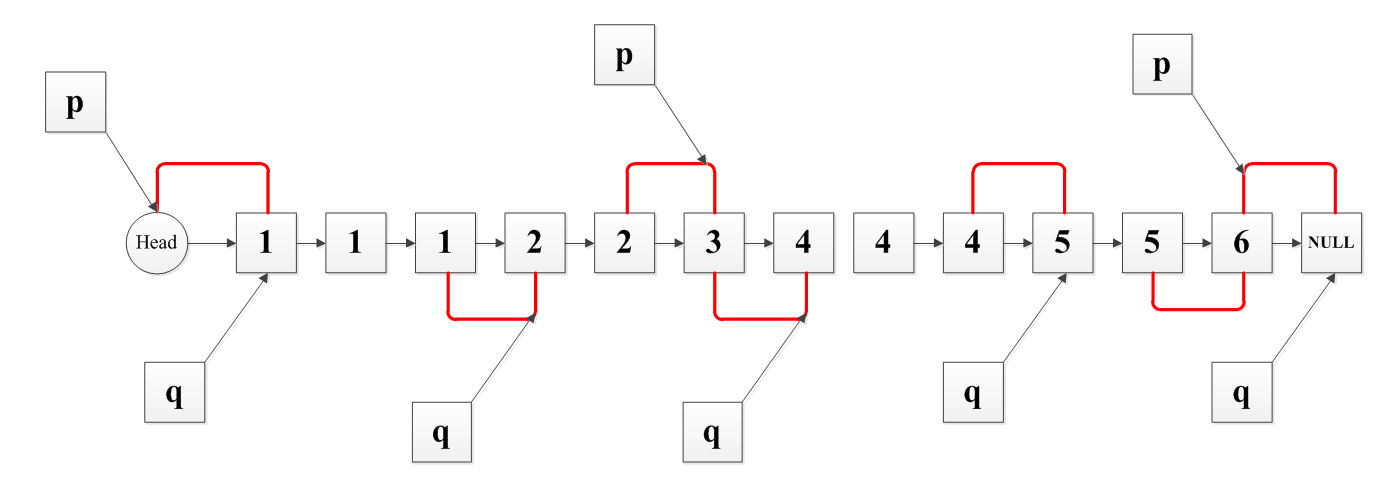
先建一个头结点,返回的时候返回这个头结点。
再建两个临时结点p、q,p用来作存储结点,q用来跳过重复结点。如图中第二个q的位置,先判断p的下一个结点位置是否与q一样,不一样的话先把q的下一个结点位置存到p的下一个结点,这样就先跳过了前面的重复结点。如果p的下一个结点是一样的,那就是图中第二个p的位置那里,这个时候证明了当前的q结点是不重复的,此时p直接存储q结点。
1 | /* |
代码实现
1 | class Solution { |