前言
最近玩AIGC玩得不亦乐乎(我的视频账号),对相关的技术也产生了浓厚的兴趣,所以也了解了一些机器学习相关的知识,也自己动手折腾了一下。
正好也挺久没水博客了呢,今天正好有时间,顺便水一篇吧。
最近这两年随着ChatCPT、Stable Diffusion等生成式AI极速发展,各种AI模型也如雨后春笋般涌现,现在各大厂都在训练大模型,以及开发AIGC平台。
NVIDIA Triton Inference Server是一个针对CPU和GPU进行优化的云端推理的解决方案,支持绝大部分主流的模型框架,包括TensorFlow、TensorRT、PyTorch、ONNX Runtime等,为我们在生产环境中部署及使用AI模型提供了极大的便利,估计现在很多大厂开发的AIGC平台都用到Triton或者其它类似的服务化框架(比如TensorFlow Serving、Torch Serve、Kubeflow等),所以学习了Triton的一些基础架构和设计原理后,动手部署并且用了一下,顺便水一篇文章。

实践
Docker WSL2安装
从0编译Triton服务端应该会非常麻烦,一定会被不计其数的依赖报错困扰半天,所以我直接用Docker来部署。
由于我用的是Windows,所以需要在安装Docker Desktop来使得WSL2可以使用Docker CLI以及Docker Daemon等核心组件,具体安装以及设置过程这里就不多做赘述,直接到Docker官网及Windows官网查阅相关资料step by step即可。
注册&登录NGC平台账号
NGC简单来说就是NVIDIA的一个官方软件仓库,仓库里有很多编译好的软件、Docker镜像等,你需要注册NGC并生成api key,用这个api key来登录NGC并下载里面的镜像。具体可参考官方教程,比较简单,这里也不过多赘述。
完成注册后直接使用指令登录即可
1 | docker login nvcr.io |
之后会需要输入用户名以及api key,出现 Login Successed 即登录成功。
拉取镜像
接下来就要拉取镜像了
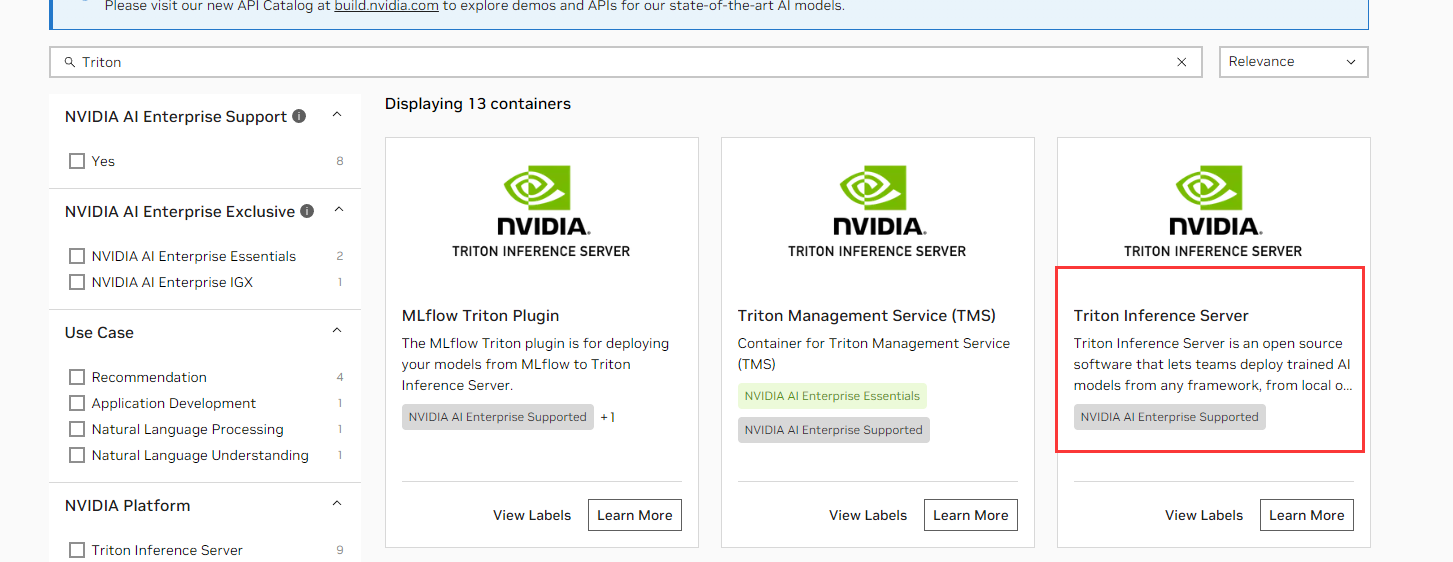
从官方文档可以看到,xx.yy-py3 就是能支持Tensorflow、PyTorch等主流模型框架的Triton服务端镜像,而下面还有个 xx.yy-py3-sdk 镜像包含了客户端相关库、例子可以让我们请求服务端,以方便测试。这两个镜像都下载下来,前者是服务端镜像,后者是客户端测试镜像。
点进来可以找到镜像路径,直接copy即可,然后拉取镜像
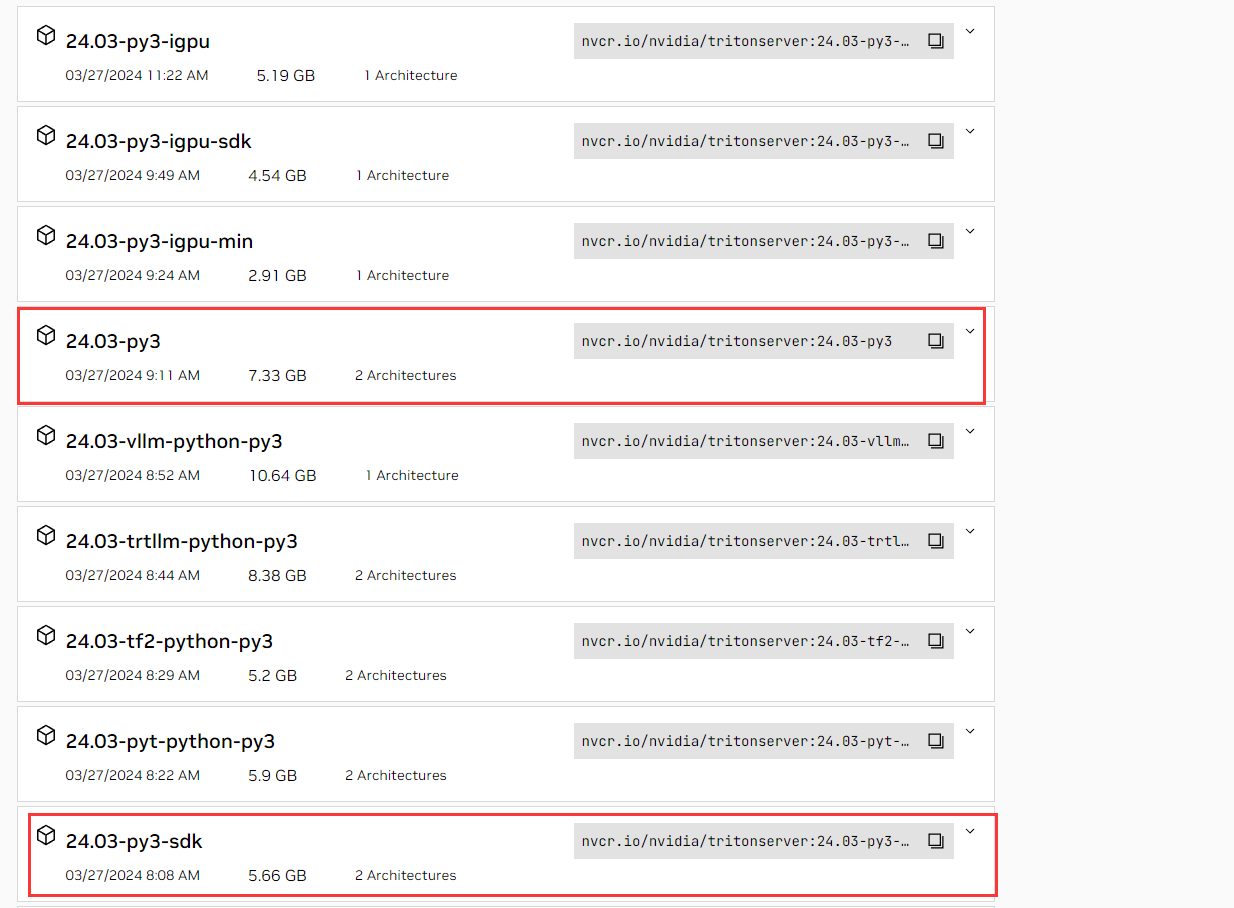
1 | docker pull nvcr.io/nvidia/tritonserver:24.03-py3 |
准备测试模型和数据
接下来需要先准备测试模型和数据,Triton Server仓库准备了很多onnx模型和测试图片,直接拿来用就行了。
先下载仓库1
git clone -b r22.12 https://github.com/triton-inference-server/server.git
执行fetch_models.sh,下载ONNX测试模型1
2cd server/docs/examples
./fetch_models.sh
服务启动
一切准备就绪,接下来启动容器吧!1
docker run --gpus=1 --rm --net=host -v ${PWD}/model_repository:/models nvcr.io/nvidia/tritonserver:24.03-py3 tritonserver --model-repository=/models
挑几个重要参数说说
- -gpus=1:代表是否启动GPU容器,如果该值为0,则Triton将运行在CPU Only模式,此时Triton的吞吐量和单个request的执行延迟会大幅增加,建议在条件允许的情况下默认打开。
- -v:代表目录挂载。这里我们将examples下的model_repository目录挂载到了/models下
- tritonserver:即代表我们要执行的二进制程序是tritonserver
- –model-repository=/models:用于指定模型的仓库位置,由于我们之前将我们宿主机的模型挂载到容器的/models目录下,所以这里写/models就好了
验证服务可用性
发个HTTP请求获取服务器的状态(这里说明一下,启动容器后默认会占用3个端口,8000为http服务端口,8001为GRPC服务端端口,8002为metrics端口,启动服务时可以看到相关信息)1
curl -v localhost:8000/v2/health/ready
得到响应1
2
3
4
5
6
7
8
9
10
11
12
13
14* Trying 127.0.0.1:8000...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8000 (#0)
> GET /v2/health/ready HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/7.68.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Content-Length: 0
< Content-Type: text/plain
<
* Connection #0 to host localhost left intact
可以看出来服务是正常的
验证推理服务
既然服务状态正常,那接下来看看推理是否正常,之前拉取的第二个镜像现在就派上了用场1
2docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:24.03-py3-sdk
/workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg
得到响应1
2
3
4Image '/workspace/images/mug.jpg':
15.349571 (504) = COFFEE MUG
13.227469 (968) = CUP
10.424896 (505) = COFFEEPOT
可以看到Triton Server的推理结果是咖啡杯,我看了看图片确实如此,所以模型没有异常,完美!
总结
Triton Inference Server通过将模型统一放置在模型仓库中进行统一管理,使用gRPC/HTTP2接受及响应推理请求,使得Triton在保证高性能的同时,也有着极强的可用性和扩展性,怪不得大家都在用呢!我这次简单的使用只能说是大概了解了Triton的基本使用方法,它的很多特性我都还没使用到,恐怕入门都还没达到,有空再继续探索一下!
